Artificial Intelligence (AI) has become ubiquitous in the tech industry, with companies rapidly integrating AI into their workflows to boost developer productivity and reduce costs. However, as someone without deep AI expertise, I lack the motivation to wade through the complex mathematics and theoretical foundations of machine learning. My intuition told me this wasn't the path I wanted to pursue — a feeling reinforced by previous deep learning internships where I found the entire process of model construction, overnight training cycles, and constant re-evaluation frustrating rather than fulfilling.
So where should I direct my time and curiosity? I realized that behind every AI/ML application lies critical infrastructure designed to support it. Most notably, AI models depend heavily on GPUs for their computational needs. Unlike traditional CPUs, GPUs excel at the parallel processing required for machine learning — handling thousands of simultaneous calculations that would bottleneck a CPU. This infrastructure layer represents a fascinating intersection of hardware optimization and software engineering that directly enables the AI revolution we're witnessing today.
Therefore, I've decided to compile essential GPU information to build a foundational understanding, with a particular focus on running CUDA applications on NVIDIA hardware. This post won't dive deep into CUDA programming concepts, but will provide sufficient detail to get you up and running with your first application.
Introduction (CPU vs GPU)
Before programming on such hardware, there is a need to understand some
details underlying it.
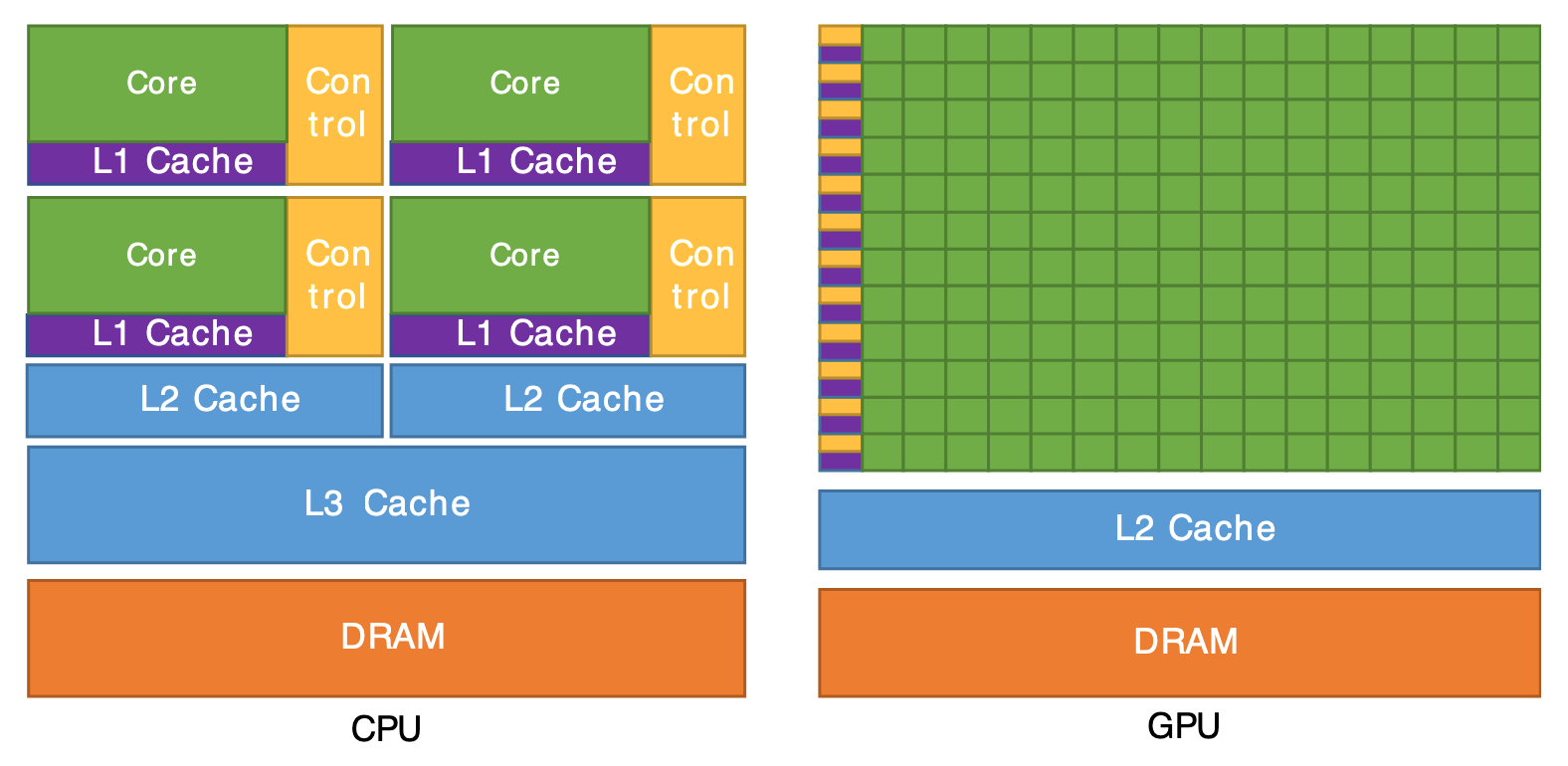 From this diagram, we can observe that both CPUs and GPUs share similar
cache architectures with L1/L2 levels. However, their core designs differ
fundamentally: CPUs feature fewer but more powerful cores
optimized for complex, sequential tasks, while GPUs contain hundreds or thousands of smaller, simpler cores. This abundance of lightweight cores enables GPUs to execute the same
instruction across many data elements simultaneously — a capability known
as parallel processing that makes them ideal for computationally
intensive workloads like machine learning.
From this diagram, we can observe that both CPUs and GPUs share similar
cache architectures with L1/L2 levels. However, their core designs differ
fundamentally: CPUs feature fewer but more powerful cores
optimized for complex, sequential tasks, while GPUs contain hundreds or thousands of smaller, simpler cores. This abundance of lightweight cores enables GPUs to execute the same
instruction across many data elements simultaneously — a capability known
as parallel processing that makes them ideal for computationally
intensive workloads like machine learning.
CUDA Device Architecture
CUDA (Compute Unified Device Architecture) is NVIDIA's parallel computing platform and programming model designed to leverage the massive parallel processing power of their GPUs. At the heart of CUDA-enabled GPUs lies a unified architecture where hundreds or thousands of cores are organized into groups called Streaming Multiprocessors (SMs). Each SM contains multiple cores that execute instructions in lockstep, enabling efficient parallel computation across large datasets—a fundamental requirement for machine learning, scientific computing, and graphics processing.
We'll explore warps — groups of 32 threads that execute instructions simultaneously — and how they enable CUDA's massive parallel execution capabilities in later blog posts.
Using CUDA
In order to take advantage of Nvidia's GPU massive parallel computing capabilities, we need matching software. That stack is called CUDA toolkit.
You can install them at
cuda downloads. Follow the steps to install the right version based on your OS. Take
note of the
GCC version you are running. Older toolkits
may require an older version of GCC compiler in order to run.
For older toolkit versions, you can find them in this archive.
1. CUDA Compiler (NVCC)
nvcc is the executable that you will use to
compile CUDA code. Once you installed the toolkit, this tool will be available
to you.
2. CUDA Libraries
In addition to the compiler, you will also get libraries (non-exhaustive) that will provide optimized functions.
- cuBLAS: GPU-accelerated Basic Linear Algebra Subprograms
- cuFFT: Fast Fourier Transform Library for GPUs
- cuRAND: Random number generation library
- cuDNN: Deep Neural Network library used for deep learning applications
Quick Example
With the CUDA toolkit installed (make sure nvcc is on your path), we're ready to run our first CUDA application. The code
below queries and displays your GPU's device properties—crucial information
for understanding your hardware's capabilities and optimizing performance (though
we'll save optimization techniques for future posts).
Run nvcc -ccbin g++-11 main.cu -o main && ./main to compile and run the above code. Obviously, you should swap out the
g++ based on the toolkit version you have installed.
When you compile CUDA applications with nvcc, the CUDA runtime header is automatically included. The nvcc compiler implicitly includes the necessary CUDA headers,
including cuda_runtime.h , so your CUDA
kernel launches, memory management functions, and other CUDA runtime API
calls will work without explicit inclusion.
Conclusion
This introduction barely scratches the surface of CUDA programming and NVIDIA GPU architecture. There's a vast landscape of concepts — from memory hierarchy and thread synchronization to kernel optimization and performance tuning — that we'll need to explore before building efficient, production-ready applications.